Our paper "PreAdapter: Pre-training Language Models on Knowledge Graphs" has been accepted on ISWC 2024
28.06.2024Our paper proposes a novel adapter-based approach to integrate knowledge from knowledge graphs into large language models (LLMs).
Abstract
Pre-trained language models have demonstrated state-of-the- art performance in various downstream tasks such as summarization, sentiment classification, and question answering. Leveraging vast amounts of textual data during training, these models inherently hold a certain amount of factual knowledge, which is particularly beneficial for knowledge-driven tasks such as question answering. However, the knowledge implicitly contained within the language models is not complete. Consequently, many studies incorporate additional knowledge from knowl- edge graphs, which provide an explicit representation of knowledge in the form of triples.
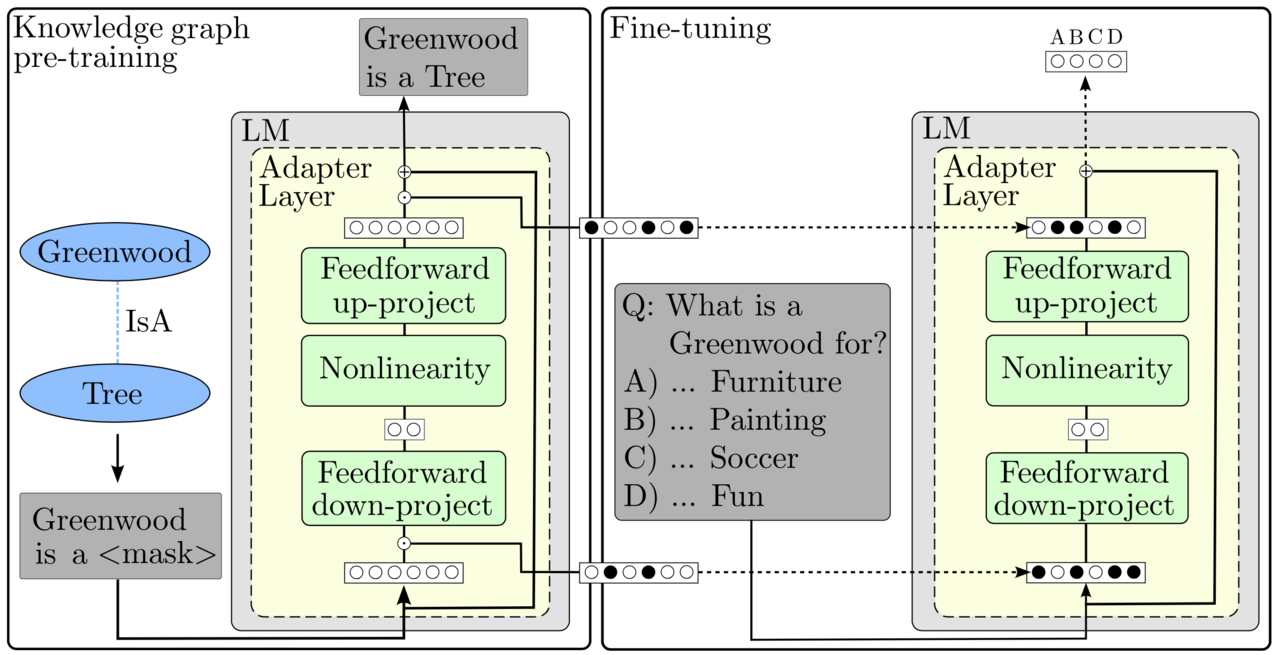
Seamless integration of this knowledge into language models remains an active research area. Direct pre-training of language models on knowledge graphs followed by fine-tuning on downstream tasks has proven ineffective, primarily due to the catastrophic forgetting effect.
Many approaches suggest fusing language models with graph embedding models to enrich language models with information from knowledge graphs, showing improvement over solutions that lack knowledge graph integration in downstream tasks. However, these methods often require additional computational overhead, for instance, by training graph embedding models.
In our work, we propose a novel adapter-based method for integrating knowledge graphs into language models through pre-training. This approach effectively mitigates catastrophic forgetting while ensuring access to knowledge during fine-tuning on downstream tasks.
Experimental results on multiple choice question answering tasks demon- strate performance improvements compared to baseline models without knowledge graph integration and other pre-training-based knowledge integration methods.
