Theses
Master Theses
Abstract:
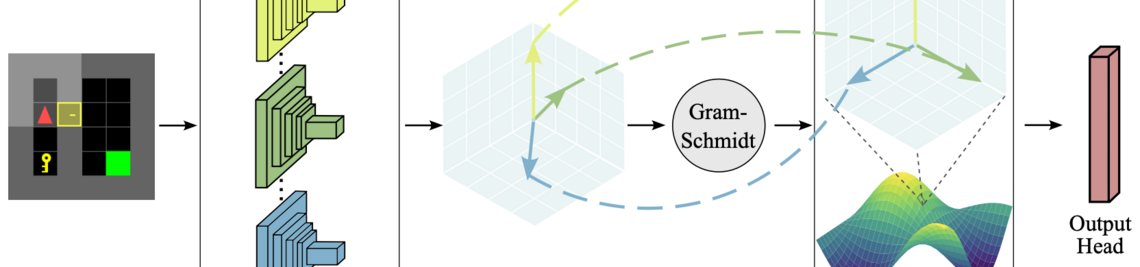
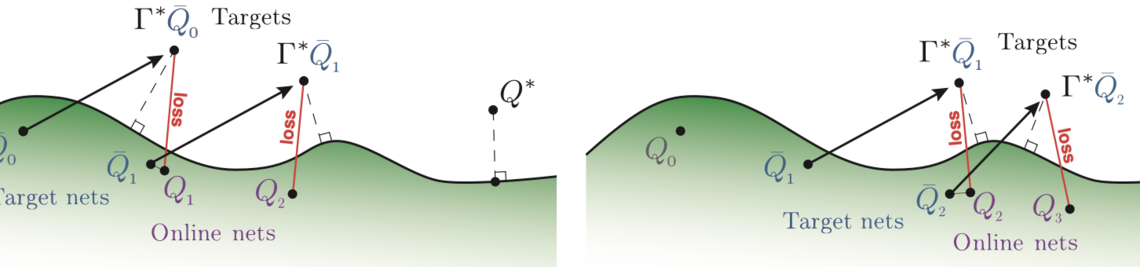
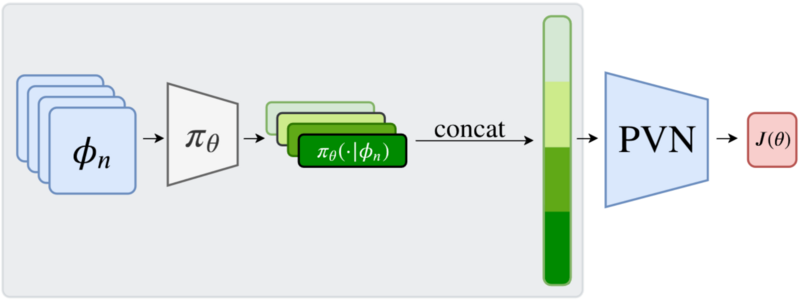
In current actor-critic reinforcement learning algorithms the critic has to implicitly learn about the non-stationary policy embodied by the actor during training. This in turn leads to a delayed learning reaction of the critic, as it always lacks behind the actor. Policy-Conditioned Value Functions explicitly include a representation of the policy, to the critic. Earlier research has shown that this method is effective in Reinforcement Learning (Francesco Faccio, Louis Kirsch, and Jürgen Schmidhuber. Parameter-Based Value Functions. 2021). Fingerprinting is a scalable method to represent a policy in such a setting (Jean Harb, Tom Schaul, Doina Precup, and Pierre-Luc Bacon. Policy Evaluation Networks, Francesco Faccio, Aditya Ramesh, Vincent Herrmann, Jean Harb and Jürgen Schmidhuber. General Policy Evaluation and Improvement by Learning to Identify Few But Crucial States. 2022). The Idea of Fingerprinting is that a learnable set of probe-states is forwarded through the policy. The resulting response is concatinated and used as the presentation of the policy. This has the advantage that Fingerprinting is agnostic to the internal structure of the policy. However this might also miss an oportunity to gain more information about the policy. In this thesis project you will try to modify the fingerprinting method and show that this modification performs better in representation tasks such as reinforcement learning with policy-conditioned value functions. A possible modification would be to aggregate across activations of hidden layer of the policy network together with the final output.
Supervisor: Sebastian Griesbach
Required skills: Experience with Deep Reinforcement Learning (for example by completing an according lecture), Experience with Python and a common Deep Learning Framework (e.g. PyTorch)
If you are intressted in this project contact me via e-mail.