SimLoss: Class Similarities in Cross Entropy
23.06.2020Our paper “SimLoss: Class Similarities in Cross Entropy” was accepted for publication at ISMIS 2020.
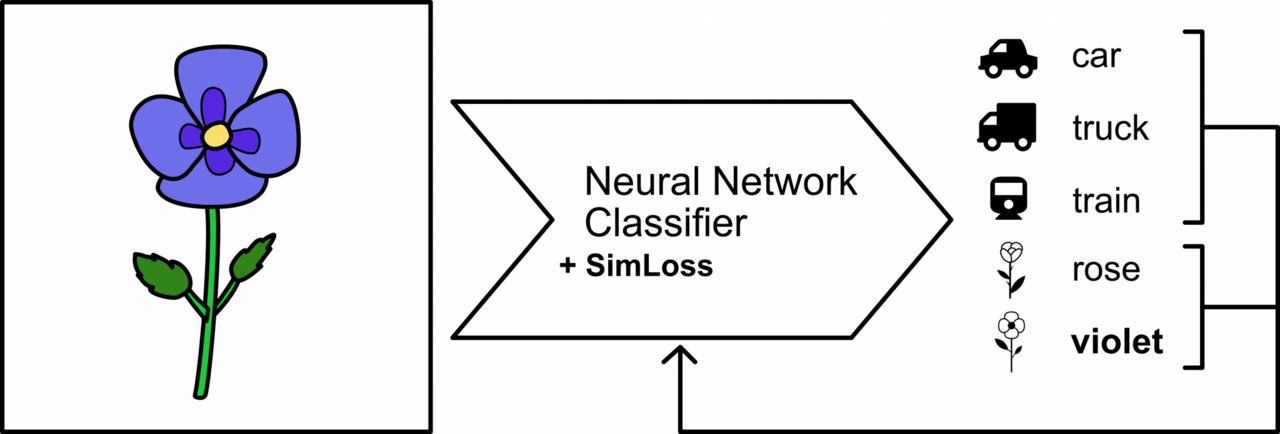
Roses are red, violets are blue,
both are somehow similar, but the classifier has no clue.
— Common Proverb
Humans have an intuition for the similarity of terms and concepts. For example, calling a rose “violet” is less strange than calling it “truck”, as we know that “rose” and “violet” are both flowers and thus similar to each other. While these similarities are self-evident for us, neural network classifiers do not have such prior knowledge. Classifiers being aware of class relations would result in making less severe mistakes in case of misclassification.
In our recent paper we propose SimLoss, a simple modification to the commonly used Categorical Cross Entropy (CCE) loss function, that allows us to introduce background knowledge in the form of class similarities into neural network classifiers.
For this, we augment CCE with a matrix containing class similarities (0: not at all similar, 1: identical or interchangeable). We also propose two matrix generation techniques that exploit class order and general class similarity, such that we can use any similarity metric (e.g. human judgement or semantic similarity using word embeddings). Both techniques have a hyper-parameter that controls how much the similarity matrix affects the training procedure.

We compare SimLoss to CCE on two tasks and three datasets and show that SimLoss is able to significantly outperform CCE on metrics measuring either more or less specific predictions, depending on the hyper-parameter choice. For example, for Image Classification on CIFAR-100, we found that smaller similarity matrix influences lead to improved Accuracy, while larger influences lead to improved performance on predicting the superclass of the given example (e.g. “rose” and “violet” have the superclass “flower”). In case of misclassifications, the neural network made less severe mistakes and predicted more similar classes.
For more information, take a look into the paper. Our PyTorch code and additional resources can be found on Github.
