Evaluating Explainable Artificial Intelligence
25.03.2020Our paper “Evaluation of post-hoc XAI approaches through synthetic tabular data” was accepted for publication at ISMIS 2020.

Deep Neural Networks are powerful artificial intelligence (AI) architectures that manage to find very complex relationships in data. While their performance is exceptional in many tasks, their design does not allow humans to understand the reasoning behind their decisions.

Since this may prevent the use of these architectures in areas with high risk decisions that effect human lives (such as autonomous driving, medical or financial sectors), there has been recent increasing research on post-hoc explainable artificial intelligence (XAI). Post-hoc XAI approaches are deployed on fully functional and independent AI systems in order to gain insights into which parts of the data were responsible for a certain AI decision.
While many post-hoc XAI approaches were proposed in recent years, assessing whether their explanations are truly faithful to the AI to be explained is a challenging prospect. Additionally, many XAI approaches are developed and evaluated on image data, with unkown performance on other data types.
For our DeepScan project, where we detect fraudulent behavior in tabular ERP system data, we aim to investigate how established post-hoc XAI approaches perform on tabular data. To gain first insights, we investigate XAI performance on categorical data where feature relationships can often be described via Boolean functions.
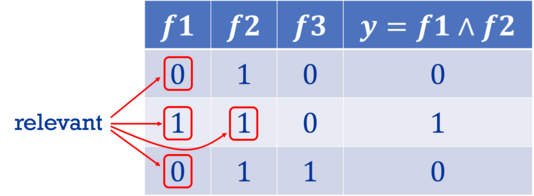
As seen in Figure 1, we create synthetic datasets based on commonly appearing Boolean operations such as AND, OR, and XOR, and define when input features are considered relevant to the output of the operation, by adapting an existing definition of Boolean feature influence to the domain of XAI.
We also have to take into account that an explanation which does not match our correct relevance may not necessarily be caused by a poorly performing XAI approach, but might instead be caused by the correct explanation of a poorly performing AI system. For this, we propose an evaluation setting that allows the separation of AI system and XAI approach on our synthetic data.
With our proposed setting we evaluate 8 state-of-the-art post-hoc XAI approaches on different types of Boolean functions. We find that many XAIs even fail to faithfully explain the basic non-linear XOR operation. Even on linear Boolean functions, which appear to be easier to explain for most XAIs, performance of XAI approaches quickly and consistently decreases with increasing function complexity. With XAI appoaches starting to struggle even on comparably simple categorical data correlations, the obtained results cast doubt on whether the evaluated approaches should be applied to highly complex real life tasks.
The datasets generated in our experiments may be used to gain first insights into XAI performance on categorical tabular data and are available as benchmark datasets.
For more information, check out the paper.
