Our Paper "Data Generation for Explainable Occupational Fraud Detection" was accepted at KI 2024
21.06.2024In our paper, we use multi-agent systems to simulate labeled company data, allowing us to automatically detect and explain occupational fraud in otherwise unlabeled data.
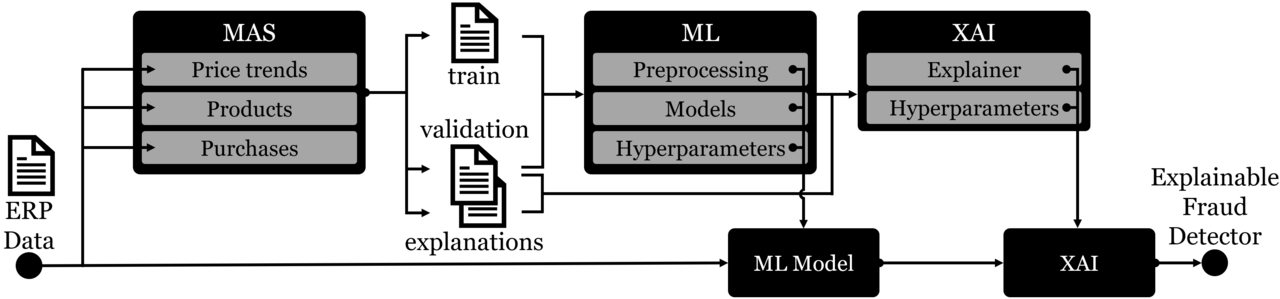
We are glad to be featured in KI 2024, and look forward to presenting our most recent work here in Würzburg. Our proposed work uses a data simulation to provide labeled data for occupational fraud detection, allowing us to automatically detect and explain occupational fraud.
Abstract:
Occupational fraud, the deliberate misuse of company assets by employees, causes damages of around 5% of yearly company revenue. Recent work therefore focuses on automatically detecting occupational fraud through machine learning on the company data contained within enterprise resource planning systems. Since interpretability of these machine learning approaches is considered a relevant aspect of occupational fraud detection, first works have already integrated post-hoc explainable artificial intelligence approaches into their fraud detectors. While these explainers show promising first results, systematic advancement of explainable fraud detection methods is currently hindered by the general lack of ground truth explanations to evaluate explanation quality and choose suitable explainers. To avoid expensive expert annotations, we propose a data generation scheme based on multi-agent systems to obtain company data with labeled occupational fraud cases and ground truth explanations. Using this data generator, we design a framework that enables the optimization of post-hoc explainers for unlabeled company data. On two datasets, we experimentally show that our framework is able to successfully differentiate between explainers of high and low explanation quality, showcasing the potential of multi-agent-simulations to ensure proper performance of post-hoc explainers.
