SemEval'24 Task 4 & Task 6 Participation - First Place on Average for Task 4!
01.03.2024We participated in two SemEval tasks and placed first on average in SemEval'24 Task 4!! OTTERly fantastic!
We successfully participated in two SemEval Challenges this year!
First, our students participated in Task 4: "Multilingual Detection of Persuasion Techniques in Memes", revolving around the goal to build models for identifying a number of rhetorical and psychological techniques in the textual content of a meme only (subtask one) and in a multimodal setting in which both the textual and the visual content are to be analysed together (subtask two).
We participated in the context of the "Machine Learning for Natural Language Processing" Praktikum at our chair, where we placed on average 1st (!!) for the textual, mulitlingual subtask and 8th for the multimodal subtask - OTTERly fantastic, if you ask us!
Abstract (not yet published):
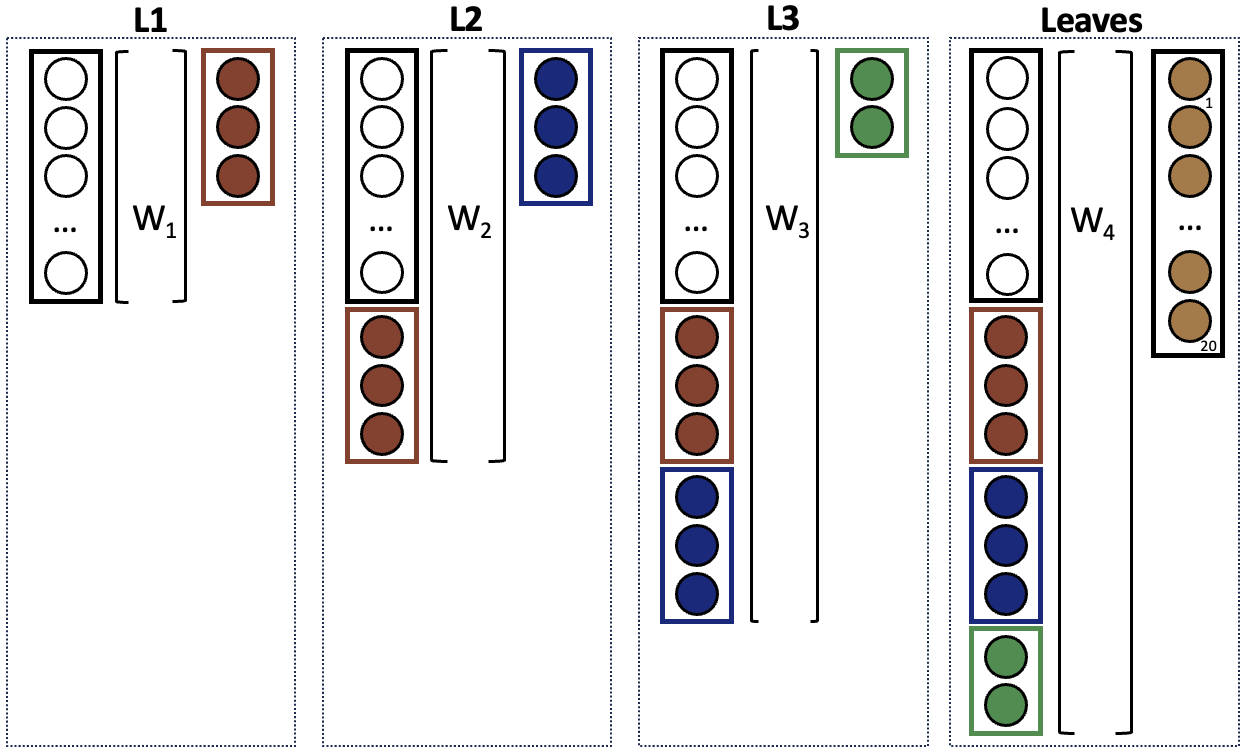
This paper presents our approach to classifying hierarchically structured persuasion techniques used in memes for Task 4 SemEval 2024. We developed a custom classification head designed to be applied atop of a Large Language Model, reconstructing hierarchical relationships through multiple fully connected layers. This approach incorporates the decisions of foundational layers in subsequent, more fine-grained layers. To improve performance, we conducted a small hyperparameter search across various models and explore strategies for addressing uneven label distributions including weighted loss and thresholding methods. Furthermore, we extend our pre-processing to compete in the multilingual setup of the task by translating all documents into English. Finally, our system achieved third place on the English dataset and first place on the Bulgarian, North Macedonian and Arabic test datasets.
Secondly we also participated in the "Shared-task on Hallucinations and Related Observable Overgeneration Mistakes (SHROOM)", with the goal to reliably identify "hallucinations" in LLMs (when it produces inaccurate but fluent output). Here we relied entirely on prompting LLMs to detect hallucinations and didn't conduct any finetuning. This places us 12th/48 on the not yet deduplicated leaderboard.
Abstract (not yet published):
We present an intuitive approach for hallucination detection in LLM outputs that is modeled after how humans would go about this task. We engage several LLM "experts" to independently assess whether a response is hallucinated. For this we select recent and popular LLMs smaller than 7B parameters. By analyzing the log probabilities for tokens that signal a positive or negative judgment, we can determine the likelihood of hallucination. Additionally, we enhance the performance of our "experts" by automatically refining their prompts using the recently introduced OPRO framework. Furthermore, we ensemble the replies of the different experts in a uniform or weighted manner, which builds a quorum from the expert replies. Overall this leads to accuracy improvements of up to 10.6 p.p. compared to the challenge baseline. We show that a Zephyr 3B model is well suited for the task. Our approach can be applied in the model-agnostic and model-aware subtasks without modification and is flexible and easily extendable to related tasks.
