Datenimport
Das PaDaWaN-Framework besitzt verschiedene Tools und Schnittstellen um alle für den Datenimport notwendigen Prozesse durchführen zu können:
- Mit einem generischen Importer können die gängigsten Datenformate (CSV, XML, Text) importiert werden, indem in einer dafür vorgesehenen Importer-Sprache eine Import-Konfiguration definiert wird, die den Importer regelt.
- Mit speziellen Java-Importer-Klassen können für komplexe Datendomänen Importer geschrieben werden, um jeden gewünschten Datenbestand auf das PaDaWaN-Datenmodell abbilden zu können. Die abstrakten Importer-Klassen bieten dabei unterstützenden Zugriff auf die jeweiligen Tabellen des Datenbankschemas.
- Daten können mit direkten SQL-Statements direkt in die jeweiligen Tabellen geschrieben werden
- Um die Quelldaten für die Verwendung in einem DataWarehouse entsprechend anonymisieren zu können gibt es ein Anonymisierungs-Tool, das als Service in den ETL-Prozess eingebunden werden kann.
Nach dem Befüllen der Datenbank wird mit einem Indexer-Tool der Datenbestand der Datenbank mit dem Solr-Index synchronisiert.
Abbildung 1 illustriert den ETL-Prozess von den Quelldaten bis hin zur Abfrage des Systems.
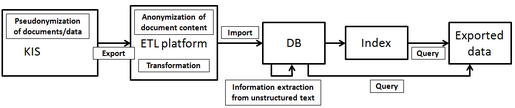
Abbildung 1: ETL-Prozessfluss zur Befüllung eines PaDaWaN-Systems