UIMA Ruta (Text Annotation)
UIMA Ruta
The UIMA Ruta language is an imperative rule language extended with scripting elements. A rule defines a pattern of annotations with additional conditions. If this pattern applies, then the actions of the rule are performed on the matched annotations. A rule is composed of a sequence of rule elements and a rule element essentially consists of four parts: A matching condition, an optional quantifier, a list of conditions and a list of actions. The matching condition is typically a type of an annotation by which the rule element matches on the covered text of one of those annotations. The quantifier specifies, whether it is necessary that the rule element successfully matches and how often the rule element may match. The list of conditions specifies additional constraints that the matched text or annotations need to fulfill. The list of actions defines the consequences of the rule and often creates new annotations or modifies existing annotations.
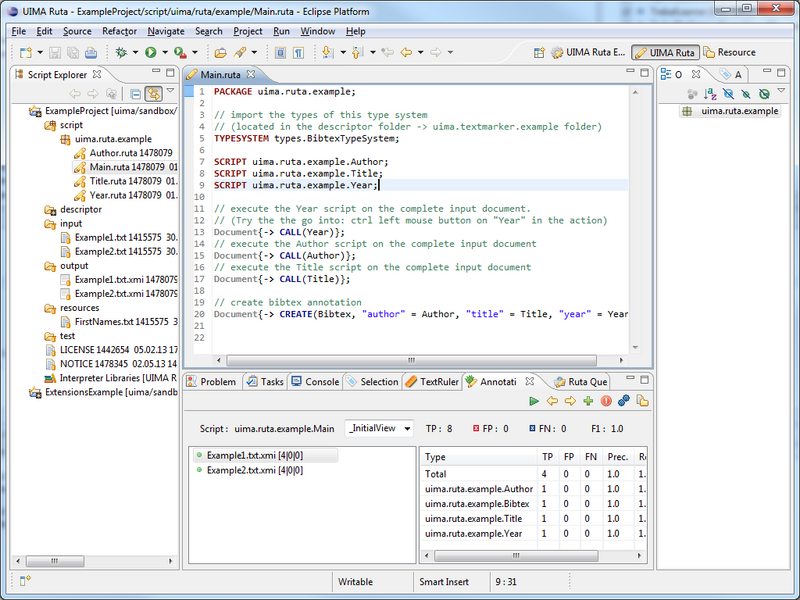
The UIMA Ruta Workbench was created to facilitate all steps in creating Analysis Engines based on the UIMA Ruta language. Here is a short overview of included features:
Editing support: The full-featured editor for the UIMA Ruta language provides syntax and semantic highlighting, syntax checking, context-sensitive auto-completion, template-based completion, open declaration and more.
Rule Explanation: Each step in the matching process can be explained: This includes how often a rule was applied, which condition was not fulfilled, or by which rule a specific annotation was created. Additionally, profile information about the runtime performance can be accessed.
Automatic Validation: UIMA Ruta scripts can automatically validated against a set of annotated documents (F1 score, test-driven development) and even against unlabeled documents (constraint-driven evaluation).
Rule learning: The supervised learning algorithms of the included TextRuler framework are able to induce rules and, therefore, enable semi-automatic development of rule-based components.
Query: Rules can be used as query statements in order to investigate annotated documents.
More information at: